Prior approaches that have used content analysis to rank broad queries on the WWW cannot distinguish between authoritative and non-authoritative pages (e.g., they fail to detect spam pages). Hence the ranking tends to be poor and search services have turned to other sources of information besides content to rank results. We next describe some of these ranking strategies, followed by our new approach to authoritative ranking - which we call Hilltop.
Ranking Based on Human Classification: Human editors have been used by companies such as Yahoo! and Mining Company to manually associate a set of categories and keywords with a subset of documents on the web. These are then matched against the user's query to return valid matches. The trouble with this approach is that: (a) it is slow and can only be applied to a small number of pages, and (b) often the keywords and classifications assigned by the human judges are inadequate or incomplete. Given the rate at which the WWW is growing and the wide variation in queries this is not a comprehensive solution.
Ranking Based on Usage Information: Some services such as DirectHit collect information on: (a) the queries individual users submit to search services and (b) the pages they look at subsequently and the time spent on each page. This information is used to return pages that most users visit after deploying the given query. For this technique to succeed a large amount of data needs to be collected for each query. Thus, the potential set of queries on which this technique applies is small. Also, this technique is open to spamming.
Ranking Based on Connectivity: This approach involves analyzing the hyperlinks between pages on the web on the assumption that: (a) pages on the topic link to each other, and (b) authoritative pages tend to point to other authoritative pages.
PageRank [Page et al 98] is an algorithm to rank pages based on assumption b. It computes a query-independent authority score for every page on the Web and uses this score to rank the result set. Since PageRank is query-independent it cannot by itself distinguish between pages that are authoritative in general and pages that are authoritative on the query topic. In particular a web-site that is authoritative in general may contain a page that matches a certain query but is not an authority on the topic of the query. In particular, such a page may not be considered valuable within the community of users who author pages on the topic of the query.
An alternative to PageRank is Topic Distillation [Kleinberg 97, Chakrabarti et al 98, Bharat et al 98, Chakrabarti et al 99]. Topic distillation first computes a query specific subgraph of the WWW. This is done by including pages on the query topic in the graph and ignoring pages not on the topic. Then the algorithm computes a score for every page in the subgraph based on hyperlink connectivity: every page is given an authority score. This score is computed by summing the weights of all incoming links to the page. For each such reference, its weight is computed by evaluating how good a source of links the referring page is. Unlike PageRank, Topic Distillation is only applicable to broad queries, since it requires the presence of a community of pages on the topic.
A problem with Topic Distillation is that computing the subgraph of the WWW which is on the query topic is hard to do in real-time. In the ideal case every page on the WWW that deals with the query topic would need to be considered. In practice an approximation is used. A preliminary ranking for the query is done with content analysis. The top ranked result pages for the query are selected. This creates a selected set. Then, some of the pages within one or two links from the selected set are also added to the selected set if they are on the query topic. This approach can fail because it is dependent on the comprehensiveness of the selected set for success. A highly relevant and authoritative page may be omitted from the ranking by this scheme if it either did not appear in the initial selected set, or some of the pages pointing to it were not added to the selected set. A "focused crawling" procedure to crawl the entire web to find the complete subgraph on the query's topic has been proposed [Chakrabarti et al 99] but this is too slow for online searching. Also, the overhead in computing the full subgraph for the query is not warranted since users only care about the top ranked results.
Our algorithm consists of two broad phases:
(i) Expert Lookup
We define an expert page as a page that is about a certain topic and has links to many non-affiliated pages on that topic. Two pages are non-affiliated conceptually if they are authored by authors from non-affiliated organizations. In a pre-processing step, a subset of the pages crawled by a search engine are identified as experts. In our experiment we classified 2.5 million of the 140 million or so pages in AltaVista's index to be experts. The pages in this subset are indexed in a special inverted index.
Given an input query, a lookup is done on the expert-index to find and rank matching expert pages. This phase computes the best expert pages on the query topic as well as associated match information.
(ii) Target Ranking
We believe a page is an authority on the query topic if and only if some of the best experts on the query topic point to it. Of course in practice some expert pages may be experts on a broader or related topic. If so, only a subset of the hyperlinks on the expert page may be relevant. In such cases the links being considered have to be carefully chosen to ensure that their qualifying text matches the query. By combining relevant out-links from many experts on the query topic we can find the pages that are most highly regarded by the community of pages related to the query topic. This is the basis of the high relevance that our algorithm delivers.
Given the top ranked matching expert-pages and associated match information, we select a subset of the hyperlinks within the expert-pages. Specifically, we select links that we know to have all the query terms associated with them. This implies that the link matches the query. With further connectivity analysis on the selected links we identify a subset of their targets as the top-ranked pages on the query topic. The targets we identify are those that are linked to by at least two non-affiliated expert pages on the topic. The targets are ranked by a ranking score which is computed by combining the scores of the experts pointing to the target.
We consider tokens to be substrings of the hostname delimited by "." (period). A suffix of the hostname is considered generic if it is a sequence of tokens that occur in a large number of distinct hosts. E.g., ".com" and ".co.uk" are domain names that occur in a large number of hosts and are hence generic suffixes. Given two hosts, if the generic suffix in each case is removed and the subsequent right-most token is the same, we consider them to be affiliated.
E.g., in comparing "www.ibm.com" and "ibm.co.mx" we ignore the generic suffixes ".com" and ".co.mx" respectively. The resulting rightmost token is "ibm", which is the same in both cases. Hence they are considered to be affiliated. Optionally, we could require the generic suffix to be the same in both cases.
The affiliation relation is transitive: if A and B are affiliated and B and C are affiliated then we take A and C to be affiliated even if there is no direct evidence of the fact. In practice some non-affiliated hosts may be classified as affiliated, but that is acceptable since this relation is intended to be conservative.
In a preprocessing step we construct a host-affiliation lookup. Using a union-find algorithm we group hosts, that either share the same rightmost non-generic suffix or have an IP address in common, into sets. Every set is given a unique identifier (e.g., the host with the lexicographically lowest hostname). The host-affiliation lookup maps every host to its set identifier or to itself (when there is no set). This is used to compare hosts. If the lookup maps two hosts to the same value then they are affiliated; otherwise they are non-affiliated.
Considering all pages with out-degree greater than a threshold, k (e.g., k=5) we test to see if these URLs point to k distinct non-affiliated hosts. Every such page is considered an expert page.
If a broad classification (such as Arts, Science, Sports etc.) is known for every page in the search engine database then we can additionally require that most of the k non-affiliated URLs discovered in the previous step point to pages that share the same broad classification. This allows us to distinguish between random collections of links and resource directories. Other properties of the page such as regularity in formatting can be used as well.
The inverted index is organized as a list of match positions within experts. Each match position corresponds to an occurrence of a certain keyword within a key phrase of a certain expert page. All match positions for a given expert occur in sequence for a given keyword. At every match position we also store:
To avoid giving long key phrases an advantage, the number of keywords within any key phrase is limited (e.g., to 32).
Thus, we compute the score of an expert as as a 3-tuple of the form (S0, S1, S2). Let k be the number of terms in the input query, q. The component Si of the score is computed by considering only key phrases that contain precisely k - i of the query terms. E.g., S0 is the score computed from phrases containing all the query terms.
Si = SUM{key phrases p with k - i query terms} LevelScore(p) * FullnessFactor(p, q)
LevelScore(p) is a score assigned to the phrase by virtue of the type of phrase it is. For example, in our implementation we use a LevelScore of 16 for title phrases, 6 for headings and 1 for anchor text. This is based on the assumption that the title text is more useful than the heading text, which is more useful than an anchor text match in determining what the expert page is about.
FullnessFactor(p, q) is a measure of the number of terms in p covered by the terms in q. Let plen be the length of p. Let m be the number of terms in p which are not in q (i.e., surplus terms in the phrase). Then, FullnessFactor(p, q) is computed as follows:
Expert_Score = 232 * S0 + 216 * S1 + S2.
The target score T is computed in three steps:
| Alpha Phi Omega | Best Buy | Digital | Disneyland |
| Dollar Bank | Grouplens | INRIA | Keebler |
| Mountain View Public Library | Macy's | Minneapolis City Pages | Moscow Aviation Institute |
| MENSA | OCDE | ONU | Pittsburg Steelers |
| Pizza Hut | Rice University | SONY | Safeway |
| Stanford Shopping Center | Trek Bicycle | USTA | Vanguard Investments |
The same query was sent to all four search engines. We assume that there is exactly one home page in each case. Every time the home page was found within the first ten results, its rank was recorded. Figure 2 summarizes the average recall for the ranks 1 to 10 for each of the four engines: our engine Hilltop (HT), Google (GG), AltaVista (AV), and DirectHit (DH). Average recall at rank k for this experiment is the probability of finding the desired home page within the first k results.
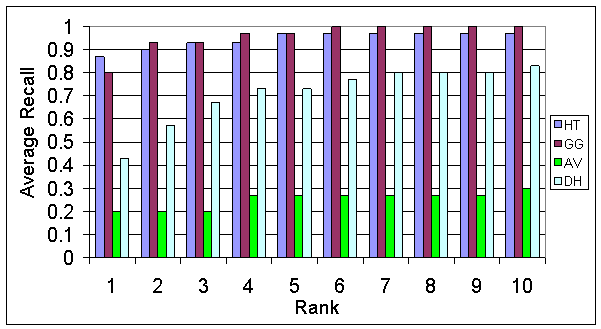
Our engine performed well on these queries. Thus, for about 87%
of the queries, Hilltop returned the desired page as the first result,
comparable with Google at 80% of the queries, while DirectHit
and AltaVista succeeded at rank 1 only in 43% and 20% of the cases,
respectively. As we look at more results, the average recall increases
to 100% for Google, 97% for Hilltop, 83% for DirectHit,
and 30% for AltaVista.
| Aerosmith | Amsterdam | backgrounds | chess | dictionary |
| fashion | freeware | FTP search | Godzilla | Grand Theft Auto |
| greeting cards | Jennifer Love Hewitt | Las Vegas | Louvre | Madonna |
| MEDLINE | MIDI | newspapers | Paris | people search |
| real audio | software | Starr report | tennis | UFO |
We then used a script to submit each query to all four search engines and collect the top 10 results from each engine, recording for each result the URL, the rank, and the engine that found it. We needed to determine which of the results were relevant in an unbiased manner. For each query we generated the list of unique URLs in the union of the results from all engines. This list was then presented to a judge in a random order, without any information about the ranks of page or their originating engine. The judge rated each page for relevance to the given query on a binary scale (1 = "good page on the topic", 0 = "not relevant or not found"). Then, another script combined these ratings with the information about provenance and rank and computed the average precision at rank k (for k = 1, 5, and 10). The results are summarized in Figure 3.
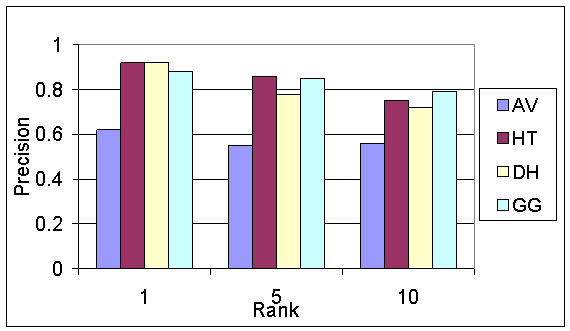
These results indicate that for broad subjects our engine returns a large percentage of highly relevant pages among the ten best ranked pages, comparable with Google and DirectHit, and better than AltaVista. At rank 1 both Hilltop and DirectHit have an average precision of 0.92. Average precision at 10 for Hilltop was 0.77, roughly equal to the best search engine, namely Google, with a precision of 0.79 at rank 10.
Hilltop most resembles the connectivity techniques, PageRank and Topic Distillation. Unlike PageRank our technique is a dynamic one and considers connectivity in a graph specifically about the query topic. Hence, it can evaluate relevance of content from the point of view of the community of authors interested in the query topic. Unlike Topic Distillation we enumerate and consider all good experts on the subject and correspondingly all good target pages on the subject. In order to find the most relevant experts we use a custom keyword-based approach, focusing only on the text that best captures the domain of expertise (the document title, section headings and hyperlink anchor-text). Then, in following links, we boost the score of those targets whose qualifying text best matches the query. Thus, by combining content and connectivity analysis, we are both more comprehensive and more precise. An important property is that unlike Topic Distillation approaches, we can prove that if a page does not appear in our output it lacks the connectivity support to justify its inclusion. Thus we are less prone to omit good pages on the topic, which is a problem with Topic Distillation systems. Also, since we use an index optimized to finding experts, our implementation uses less data than Topic Distillation and is therefore faster.
The indexing of anchor-text was first suggested in WWW Worm [McBryan 94]. In some Topic Distillation systems such as Clever [Chakrabarti et al 1998] and in the Google search engine [Page et al 98] anchor-text is considered in evaluating a link's relevance. We generalize this to other forms of text that are seen to "qualify" a hyperlink at its source, and include headings and title-text as well. Also, unlike Topic Distillation systems, we evaluate experts on their content match to the user's query, rather than on their linkage to good target pages. This prevents the scores of "niche experts" (i.e., experts that point to new or relative poorly connected pages) from being driven to zero, as is often the case in Topic Distillation algorithms.
In a blind evaluation we found that Hilltop delivers a high level of relevance given broad queries, and performs comparably to the best of the commercial search engines tested.
 Krishna Bharat is a member of the research staff at Google Inc.
in Mountain View, California. Formerly he was at Compaq Computer
Corporation's Systems Research Center, which is where the research
described here was done. His research interests include Web content
discovery and retrieval, user interface issues in Web search and task
automation, and relevance assessments on the Web. He received his Ph.D.
in Computer Science from Georgia Institute of Technology in 1996,
where he worked on tool and infrastructure support for building
distributed user interface applications.
Krishna Bharat is a member of the research staff at Google Inc.
in Mountain View, California. Formerly he was at Compaq Computer
Corporation's Systems Research Center, which is where the research
described here was done. His research interests include Web content
discovery and retrieval, user interface issues in Web search and task
automation, and relevance assessments on the Web. He received his Ph.D.
in Computer Science from Georgia Institute of Technology in 1996,
where he worked on tool and infrastructure support for building
distributed user interface applications.
|
 George Andrei
Mihaila is a Ph.D. student in the Department of Computer
Science at the University of Toronto. During the summer of 1999 he was
an intern at Compaq Computer Corporation's Systems Research Center,
which is where this research was done. His research interests
include query languages, information discovery tools, Web-based
information systems and database integration. He received his M.Sc. in
Computer Science from the University of Toronto in 1996 with the
thesis WebSQL - an SQL-like Query Language for the World Wide
Web. George Andrei
Mihaila is a Ph.D. student in the Department of Computer
Science at the University of Toronto. During the summer of 1999 he was
an intern at Compaq Computer Corporation's Systems Research Center,
which is where this research was done. His research interests
include query languages, information discovery tools, Web-based
information systems and database integration. He received his M.Sc. in
Computer Science from the University of Toronto in 1996 with the
thesis WebSQL - an SQL-like Query Language for the World Wide
Web.
|